

If you wanted to extract pricing data from an e-commerce site or monitor news sentiment, you had to hire a developer to write a Python script. This script would parse the raw HTML code, hunt for specific tags (like div class="price"), and dump the text into a database.
It was rigid. It was fragile. And frankly, it was "dumb."
If the website owner decided to change the class name from "price" to "product-cost," the entire operation would crash. If a "Accept Cookies" popup appeared, the script would get stuck.
But in 2026, we are witnessing the death of the "dumb scraper" and the rise of Agentic Web Extraction.
This shift is driven by the concept of "Browser Use"—a technological breakthrough that combines Large Language Models (LLMs) with browser automation libraries (like Playwright or Puppeteer).
Instead of telling a bot which line of code to read, we now tell an AI Agent what information to find. The agent opens a browser, "looks" at the page, dismisses popups, scrolls through dynamic content, and extracts the data based on visual context.
This article explores how the Browser Use methodology is rewriting the rules of data collection, moving us from "Code Parsing" to "Visual Intelligence."
Part 1: The Collapse of Traditional Scraping
To understand why Browser Use is revolutionary, we must first look at why the old methods are failing.
The "Structure" Trap
Traditional tools like BeautifulSoup or Selenium rely on the website's underlying structure (the DOM). They assume the website is a static document.
The Reality: Modern web apps (React, Next.js) are fluid. Content is loaded dynamically via JavaScript. Class names are often randomized (e.g.,
css-1r5k6j).The Failure: A script looking for
div.pricereturns an empty error because that element doesn't exist until a user scrolls down.
The "Context" Blindness
Old scrapers are blind to context. They extract text without understanding it.
Scenario: A product page lists two prices: "$100" (Old Price) and "$80" (Sale Price).
The Failure: A dumb scraper might grab "$100" because it appears first in the code, completely missing the fact that the item is on sale.
The "Bot" Signature
Traditional scrapers act like robots. They hit endpoints with superhuman speed (0ms delay), execute linear paths, and lack mouse movement metadata.
The Failure: Modern anti-bot systems easily identify these signatures and block the IP address before a single byte of data is collected.
Part 2: Enter the "Browser Use" Paradigm
Browser Use is not just a tool; it is a new cognitive framework for interaction, powered by our Visual AI Engine.
When developers talk about the "Browser Use Library" or the technology stack behind platforms like Promoi, they are referring to an architecture where an LLM acts as the pilot and the Browser is the vehicle.
How It Works: The Cognitive Loop
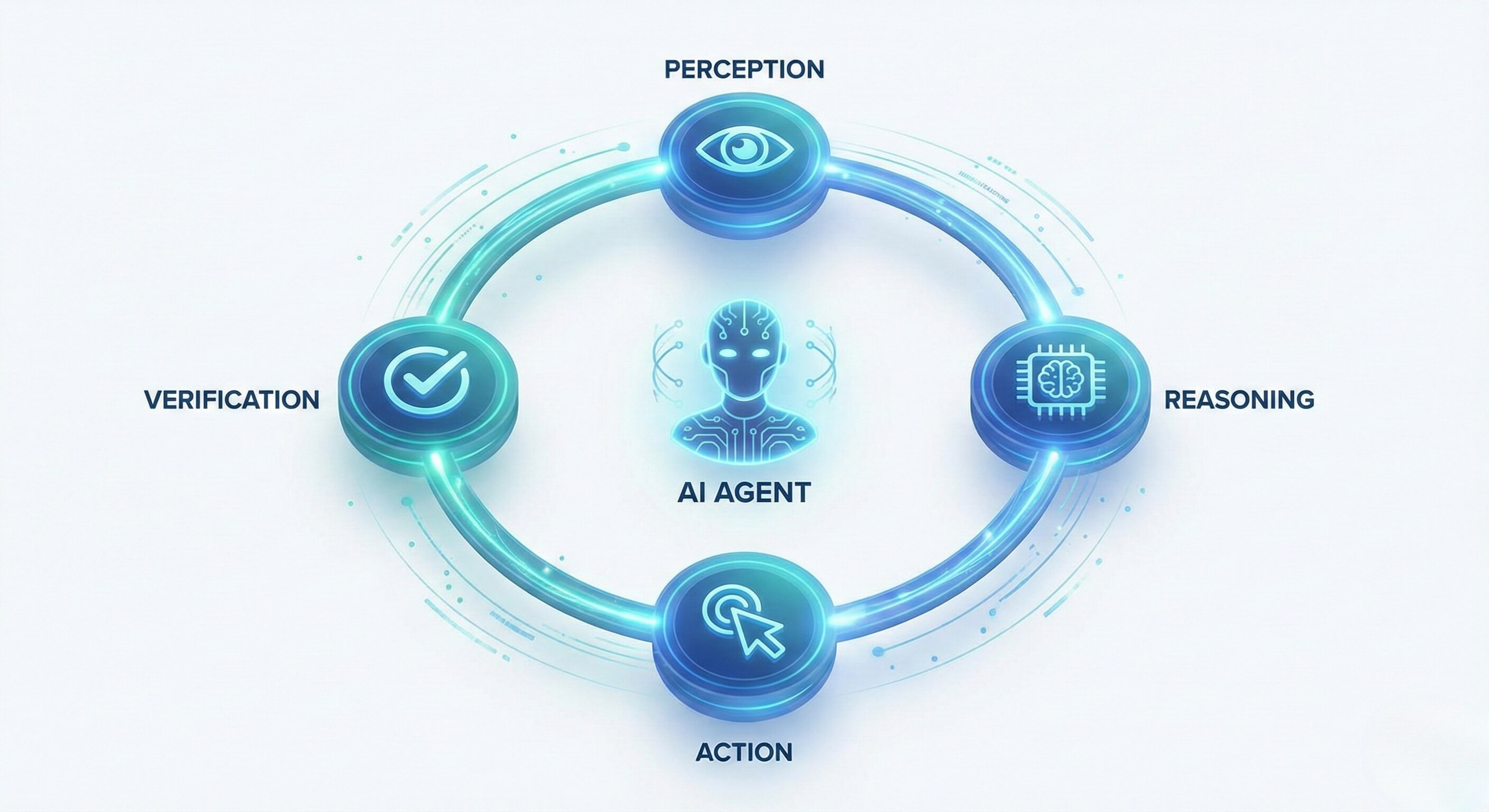
Instead of pre-programmed selectors, the process looks like this:
Snapshot (Perception): The browser renders the page. The AI takes a snapshot of the Accessibility Tree (a simplified text representation of the UI) and screenshots of the visual layout.
Reasoning (Brain): The LLM analyzes this snapshot. It asks: "Where is the price? Where is the 'Next Page' button? Is there a popup blocking my view?"
Action (Execution): The AI generates a command for the browser: "Click the button labeled 'Load More'."
Verification (Check): The AI looks at the new state of the page to confirm the data loaded.
Why This Changes Everything
Resilience: If the website design changes, the AI adapts. As long as a human can still identify the price, the AI can identify it too.
Dynamic Interaction: The AI can handle infinite scrolling, click through tabs, or hover over images to reveal details—interactions that were nightmares for static scripts.
Part 3: From "Scraping" to "Intelligence Gathering"
The most profound shift is that we are no longer just extracting data; we are extracting insight.
Structuring the Unstructured
The web is messy. A product description might be a paragraph of text. A review might be a mix of sarcasm and praise.
Old Way: Extract the raw text -> Send to a human to read.
Browser Use Way: The AI reads the text during the scraping process. You can instruct it: "Extract the price, but only if the review sentiment is positive. Also, summarize the top 3 pros and cons mentioned in the reviews."
The Output: Instead of a messy CSV file requiring cleanup, you get a clean, structured JSON object that is ready for decision-making.
Handling "Gatekeepers"
Modern data is often hidden behind logins, 2FA, or complex navigation flows.
Old Way: Hard-coding login credentials (security risk) and hoping the session doesn't expire.
Browser Use Way: The AI Worker can manage the session securely via our Anti-detect Browser. If a "Verify it's you" prompt appears, the AI can pause, request a token, or handle email verification flows autonomously, treating access management as part of the workflow.
Part 4: The Enterprise Challenge
Open Source Library vs. Managed Platform
The open-source Browser Use libraries (on GitHub) are fantastic for developers building prototypes on their local machines. However, scaling this for enterprise data operations requires more than just code.
This is where platforms like Promoi come in. We wrap the cognitive power of Browser Use technology in an enterprise-grade infrastructure.
Challenge | Local Library (Open Source) | Promoi Platform (Managed) |
|---|---|---|
Compute Cost | Runs on your laptop (eats RAM/CPU) | Runs in the Cloud (Scalable) |
Session Management | Cookies stored locally (Security risk) | Encrypted Cloud Vaults |
IP Rotation | You must buy/configure proxies | Built-in Residential IPs |
Orchestration | Single thread execution | Massive Parallel Execution (Cloud Mobile) |
Rate Limiting | You must code the delays | Compliance-Aware Pacing |
The Verdict: Use libraries to learn; use Promoi to scale.
Part 5: Strategic Use Cases
Where Visual Scraping Shines
Browser Use technology unlocks datasets that were previously "un-scrapeable."
1. Complex Market Research (Travel & Real Estate)
The Problem: Flight prices and hotel rates change dynamically based on user selection (dates, guests). The URLs are complex hashes.
The Solution: An AI Worker navigates the calendar widget, selects dynamic dates, and waits for the AJAX results to load. It then visually parses the pricing table, distinguishing between "Basic Economy" and "Business Class" columns.
2. Social Media Sentiment Analysis
The Problem: Social feeds are infinite scrolls with mixed media (text, images, video).
The Solution: The AI Worker scrolls the feed, identifying relevant posts on platforms like TikTok or Instagram. It doesn't just scrape the text; it analyzes the image context (e.g., "This is a photo of a broken product") and correlates it with the caption to determine true customer sentiment.
3. Regulatory Compliance Monitoring
The Problem: Brands need to ensure their resellers are adhering to Minimum Advertised Price (MAP) policies across thousands of small e-commerce sites.
The Solution: AI Workers visit reseller sites. They navigate through "Add to Cart to See Price" flows (which static scrapers can't do) to capture the actual selling price, ensuring compliance integrity.
Part 6: Comparison: Code Scraping vs. Visual Scraping
Feature | Code Scraping (BeautifulSoup/Selenium) | Visual Scraping (Browser Use AI) |
|---|---|---|
Navigation | Code-Defined ( | Visually-Defined ("The Blue Button") |
Maintenance | High (Breaks on UI updates) | Low (Self-Healing) |
Data Quality | Raw Text (Needs cleaning) | Structured Insight (Context-aware) |
Bot Detection | High Risk (Rigid patterns) | Low Risk (Human-like behavior) |
Dynamic Content | Fails on complex JS | Handles React/Vue/AJAX natively |
Setup Time | Hours of coding | Minutes of instruction |
FAQ: The New Era of Data Collection
Q: Is Browser Use scraping legal?
A: Data collection is a legitimate business activity, provided it respects public access norms and robots.txt policies. Promoi's agents are designed to be "Polite Crawlers"—they operate at human speeds and respect server load, making them compliant with ethical data gathering standards.
Q: Can it scrape data behind a login?
A: Yes. Because the AI Agent operates a real browser session, it can log in using credentials you provide securely. It maintains the session state just like a regular user, allowing access to gated dashboards or membership sites.
Q: How expensive is it compared to traditional scraping?
A: Compute-wise, it is more expensive; Value-wise, it is cheaper. Running an LLM + Browser requires more resources than a simple script. However, when you factor in the elimination of maintenance costs (developer hours fixing broken scripts) and the higher quality of data, the Total Cost of Ownership (TCO) is significantly lower.
Q: Does it work with multi-step forms?
A: Yes. This is its superpower. You can instruct the agent: "Go to page 1, fill out the zip code, go to page 2, select the premium plan, and tell me the final price." The AI handles the state changes between steps flawlessly.
Conclusion: The End of "Broken Data"
For too long, businesses have made decisions based on incomplete or broken data because their scrapers couldn't keep up with the modern web.
Browser Use technology fixes the pipeline. By giving AI the ability to see and reason, we turn the chaotic web into a structured database.
Whether you are a developer looking to leverage the library or a business leader looking for a platform, the message is clear: Stop parsing code. Start reading the web.



